The people at Sony are humans. They get together at the water cooler and complain about the state of affairs and all the legacy applications they have to support. Even new companies like Dropbox are going to have dark corners in their applications. Money isn’t going to solve all these problems - Apple has billions of dollars and still gave up information about users. The bigger the company, the bigger the attack surface and the more the team has to defend.
How do you prevent your company or product from being hacked given your resources are finite and you may not be able to change everything you want to?
I’ve been thinking of how Agile methods such as rapid iteration and sprints could be applied to security. With that in mind, some high level principles:
- Solutions to problems should be ranked in terms of business value
- If a solution takes more than a week or two to implement, it should be broken down into individual phases with their own business value scores
- It’s not necessary to completely solve the problem as long as you’re better off than you were before. You can make it better the next iteration
- Instead of “how can we eliminate all risk?” the better question is “how can we make an attacker’s work more difficult?”
- Detection is just as important as prevention. Look at safes – they protect valuables against a determined adversary for a given period of time, it’s still up to you to make sure you can react in that timeframe
The list above is trying to get away from the traditional security project where you spend lots of time producing documentation, shelve it, and then provide a half-assed solution to meet the deadline. Instead you break the solution into parts and try and continually produce business value. Time for a diagram:
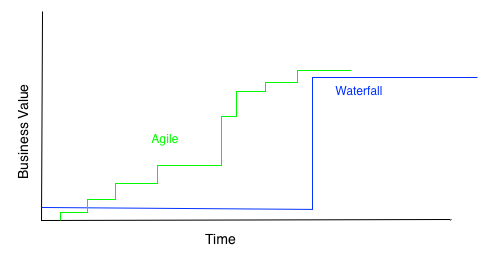
Even in the best case where you deliver full value, why not try to deliver parts of it sooner?
Look at it this way – at any point in time you know the least amount about your problem as you ever will. It’s folly to think you can solve them all with some mammoth project. Pick something, fix it, move on. You have an end goal for sure, but the path may change as you progress.
With that in mind, how do you figure out what to do?
One organization technique I’ve found helpful is the attack tree. Here you define the goal of the attacker: Steal some money, take down the site, and so forth. Then you start coming up with some high level tasks the attacker would have to do in order to accomplish the goal. The leaf nodes are the more actionable things. For example, consider what it would take to deface a website:
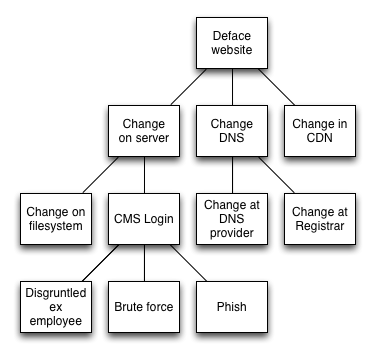
While not totally complete, this attack tree shows where the attack points are. Given that, some low effort and high value activities that could be done:
- Audit who has access to CDN, DNS, and registrar accounts
- Audit CMS accounts
Some higher effort activities would then be:
- Code fix to enforce strong passwords
- Code fix to lock out accounts after a certain period
- Code fix to centralize the authentication to the corporate directory
- Investigate two factor or SAML login with hosting providers
- Network fix to ban IPs after a certain number of attempts
- Monitor failed login attempts and investigate manually
Some of those options may be a lot of work. But if you first start with a simple password policy, build on that in the next iteration to lock out accounts, and finally tie in to another directory, you’re able to incrementally improve by making small fixes and learning as you go.
What if a group like Anonymous threatens to attack your website on the weekend? Look at the attack tree, what kind of confusion can you throw at the attacker? Change the URL of the login page? Put up a static password on the web server to view the login screen itself? Security through obscurity is not a long term fix, but as a tactical approach it can be enough to get you past a hurdle.
Too often security projects are treated in a waterfall manner. You must figure everything out front and then implement the solution, with the business value delivered at the end. Instead, treat this all as a continual learning exercise and strive to add value at each iteration. If the situation changes in the middle of the project, like an imminent threat, you’re in a better position to change course and respond.
]]>







